输入法进阶
四、段码输入法字根
段码输入法字根分为成字字根和非成字字根两类。
(一)成字字根
所谓成字字根是指形体跟成字相同的构字字根,而这个成字叫该字根的引用字。段码输入法取引用字读音作为字根读音,引用字为多音字的,字根读音取新华字典中标注次弟为(一)的读音(即最常用的读音)。如成字字根“厂”,该字根读音取它的引用字“厂”的最常用读音 “chǎng”(首字母是u),而不取“厂”的次读音“ān”。由于成字字根读音取引用字读音,所以引用字的首字母就成为该字根的首字母。
段码输入法成字字根形体主要来自现代常用独体字规范表中形体构字能力较强的独体字;因为有较强的构字能力,成字字根形体还有四个来自合体字,它们分别是 “鱼”、“骨”、“走”和“羽”。
查阅段码输入法成字字根详见《附表一:成字字根表(共127个字根)》。
与汉字构成一样,成字字根在作为汉字的偏旁部首或在汉字的不同位置时,往往会有形变,如:车(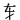 )、牛(牜)、子(孑)、月( )、牛(牜)、子(孑)、月(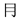 )、雨( )、雨( )、丁(丅 )、丁(丅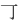 )、七( )、七(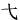 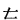 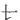 )、儿( )、儿(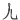 )等等,在下面的汉字拆分中要注意辨认这些变形后的字根。 )等等,在下面的汉字拆分中要注意辨认这些变形后的字根。
(二)非成字字根
由于单纯使用成字字根并不能对所有汉字进行拆分,所以段码输入法从规范和易记的角度出发,又选用了71个构字能力较强的字结构作为非成字字根对段码输入法字根进行补充。
非成字字根的读音是:先为其定义一个要义,然后取其中要义字作为引用字,最后以引用字的读音作为字根读音。非成字字根及读音详见《附表二:非成字字根表(共71个字根)》。
在非成字字根中,需要特别重视的是汉字的五大基本笔形字根,它们是:“一”(横)是包含提“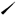 ”的所有横笔画;“丨”(竖)是包含竖左钩“亅”的所有竖笔画;“丿”(撇)是包含从右上向左下写的所有撇笔画;“丶”(点)是包含捺“ ”的所有横笔画;“丨”(竖)是包含竖左钩“亅”的所有竖笔画;“丿”(撇)是包含从右上向左下写的所有撇笔画;“丶”(点)是包含捺“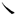 ”的所有点笔画;“”(折) 是包含带转折或拐弯的所有折笔画(如ㄥ乚 ”的所有点笔画;“”(折) 是包含带转折或拐弯的所有折笔画(如ㄥ乚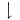 ㄑ乛ㄋ ㄑ乛ㄋ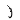  等笔画)。 等笔画)。
在非成字字根中,有2个字根形体是成字字根,但读音并不取引用字读音,故将它们放到非成字字根中,它们是:
1.字根“一”取它的似形“横”读“héng” (首字母是h)。
2.字根“口”取它的似形读汉语拼音“o” (首字母也是o)。
因为非成字字根与键盘上键位对应有一定规律,所以依据键盘上键位比较容易记忆非成字字根。段码输入法非成字字根键位对应图如《附表三:非成字字根键盘图》所示。
(三)字根码和字音码
由于每个字根都具有自己唯一的读音,那么每个字根都唯一对应有一个首字母,段码输入法把字根的首字母作为该字根参与汉字输入的编码,并简称为字根码;同时,段码输入法把汉字的首字母作为代表汉字读音参与汉字输入的编码,并简称为字音码。但字音码跟字根码不同的是,多音汉字可以有多个字音码。如汉字“厂”的字音码可以是“u”,也可以是“a”。
五、汉字拆分
我们在前面使用音形简码编码输入时知道:除第一码是字音码外,第二码、第三码是要先从汉字中拆分出字根后才能用字根码编码输入的,所以汉字拆分是汉字编码输入的前提。
段码输入法的汉字拆分是指:先把一个汉字拆分为两个以上(含两个)段码输入法字根,然后将拆分出来的字根按拆分的先后顺序排成字根序列。
汉字拆分的基本规则是:取大优先,兼顾直观。
(一)取大优先
汉字拆分的取大优先是指:优先选取汉字中笔画数较大的字根进行汉字拆分,尽量缩小汉字拆分的字根个数。
1.取大优先一般是按笔顺选取笔画数较大字根的,选取字根的次序也是按笔顺进行。以对“菇”字拆分为例:第一笔按笔顺可选取的字根有[一](加注:为便于区别字根与汉字,文中的字根和字根序也一律用方括号括起来)、[十]、[艹]3个字根,取笔画数较大的字根[艹]为“菇”字的第1排序字根。此时“菇”字的拆分已进行到第3笔,从第4笔起按笔顺可选取的字根有[]、[女]2个字根,取笔画数较大的字根[女]为“菇”字的第2排序字根。此后,在第7笔起和第9笔起,以此取大优先方法,分别选取字根[十]和字根[口](因字结构“古”不是字根,故第7笔起不能选取“古”作为字根)。至此,“菇”字全部拆分完毕,“菇”字可拆分为字根序[艹女十口]。
2.汉字拆分的取大优先,还可以按连结(相交或相接)选取字根。按连结选取字根的连结对象是笔画或字构件(段码输入法把笔顺连续的若干笔画构成的字结构叫字构件。如字结构人,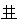 , ,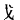 ,鼠等都属于字构件)。如对汉字“曹”的拆分,其第1笔的笔画“一”与第5至6笔组成的字构件“ ,鼠等都属于字构件)。如对汉字“曹”的拆分,其第1笔的笔画“一”与第5至6笔组成的字构件“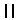 ”相交可组成字根[艹],所以对“曹”字拆分不取[一冂艹一日]拆分,应取[艹日日]拆分;对汉字“日”的拆分,其前2笔组成的字构件“冂”与第4笔的笔画“一”相接可组成字根[口],所以对“日”字拆分不取[冂二]拆分,应取[口一]拆分;对汉字“戊”的拆分,其第1笔的笔画“一”与第3至5笔组成的字构件“”相交可组成字根[戈],所以对“戊”字拆分不取[厂丿丶]拆分,应取[戈丿]拆分;对汉字“妻”的拆分,其第1笔的笔画“一”与第5笔的笔画“丨”相交可组成字根[十],所以对“妻”字拆分不取[一 ”相交可组成字根[艹],所以对“曹”字拆分不取[一冂艹一日]拆分,应取[艹日日]拆分;对汉字“日”的拆分,其前2笔组成的字构件“冂”与第4笔的笔画“一”相接可组成字根[口],所以对“日”字拆分不取[冂二]拆分,应取[口一]拆分;对汉字“戊”的拆分,其第1笔的笔画“一”与第3至5笔组成的字构件“”相交可组成字根[戈],所以对“戊”字拆分不取[厂丿丶]拆分,应取[戈丿]拆分;对汉字“妻”的拆分,其第1笔的笔画“一”与第5笔的笔画“丨”相交可组成字根[十],所以对“妻”字拆分不取[一 丨女]拆分,应取[十 女]拆分;汉字“年”的拆分,其前2笔组成的字构件“ 丨女]拆分,应取[十 女]拆分;汉字“年”的拆分,其前2笔组成的字构件“ ”与第5至6笔组成的字构件“十”相接可组成字根[午],所以对“年”字拆分不取[一丨十]拆分,应取[午一丨]拆分。 ”与第5至6笔组成的字构件“十”相接可组成字根[午],所以对“年”字拆分不取[一丨十]拆分,应取[午一丨]拆分。
3.汉字拆分的取大优先,还可以按调配取大优先选取字根。在汉字拆分中,有时候前面选取较少笔画数的字根,后面反而可以选取更大笔画数的字根。比如对“天”字拆分,如按笔顺取大优先选取字根,则只能作[二人]拆分。但如果第1个字根选取较少笔画数的字根[一],那第2个字根就能选取更大的字根[大]。即“天”字可作[一大]拆分;同样再如对“歹”字拆分,如按笔顺取大优先选取字根,则只能作[丆丶]拆分。但如果第1个字根选取较少笔画数的字根[一],那第2个字根就能选取更大的字根[夕],即“歹”字可作[一夕]拆分;同理,即“禾”字可不作[千人]拆分,而可作[丿木]拆分。再同理,字构件“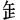 ”可不作[一止]拆分,而可作[丿正一]拆分。这种把前面字根的笔画或字构件调配给后面字根获取更大字根的方法,叫按调配取大优先选取字根。 ”可不作[一止]拆分,而可作[丿正一]拆分。这种把前面字根的笔画或字构件调配给后面字根获取更大字根的方法,叫按调配取大优先选取字根。
4.在汉字拆分中,如果某些笔画笔顺不连续或没有连结,则这些笔画不能单独拆分成一个字根,如“互”字拆分不取[二]拆分,应作[一一]拆分;“与”字拆分不取[二]拆分,应作[一一]拆分;“耳”字拆分不取[三一]拆分,应作[丁丨三]拆分。但如果按连结选取字根后,前后只相隔上一字根抽取的字构件的两个笔画,此时可视为笔顺连续了,可按笔顺连续继续进行字根选取。如字构件“”的第2笔和第5笔笔顺原来并不连续(也没有连结),即不能作[三 ]拆分。但按连结选取字根[艹]后,这两个笔画此时可视为笔顺连续了,故字构件“”可作[艹二]拆分。
5.综上,汉字按笔顺,按连结或按调配混合取大优先选取字根时,往往会有多个不同的汉字拆分方案。为从中选定一个执行方案,段码输入法规定:若字根数相同,执行含有笔画数较多的字根的拆分方案。如拆分汉字“首”,不取[丷丆目]字根序,应取[丷一自]字根序;拆分汉字“日”不取[冂二]拆分,应取[口一]拆分;对“巿”字拆分不取[十冂]拆分,应取[一巾]拆分。若字根数相同且较大字根笔画数也相同,执行按笔顺取大优先选取字根的拆分方案。如拆分汉字“亍”,不取[一丁]字根序,应取[二丨]字根序;拆分汉字“更”,不取[丆日丶]字根序,应取[一日乂]字根序。若字根数不同,执行含字根数较少的汉字拆分方案。如拆分汉字“戢”,不取[口耳丿丶]字根序,应取[口戈三]字根序。
(二)兼顾直观
汉字在按取大优先规则拆分中,特殊情况下还要兼顾字根选取的直观性:如汉字“兆”拆分不取[丿冫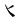 ]字根序,应取[儿冫 ]字根序;汉字“非”拆分不取[丨三丨三]字根序,应取[三三]字根序;汉字“州”拆分不取[丷丶丨丶丨]字根序,应取[丶丿丶丨丶丨]字根序;汉字“必”拆分不取[丶丶丿丶]字根序,应取[心丿]字根序;汉字“尽”拆分不取[尸 ]字根序,应取[儿冫 ]字根序;汉字“非”拆分不取[丨三丨三]字根序,应取[三三]字根序;汉字“州”拆分不取[丷丶丨丶丨]字根序,应取[丶丿丶丨丶丨]字根序;汉字“必”拆分不取[丶丶丿丶]字根序,应取[心丿]字根序;汉字“尽”拆分不取[尸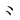 丶]字根序,应取[尸丶]字根序;汉字“曲”拆分不取[由丨]字根序,应取[日]字根序;汉字“目”拆分不取[日一]字根序,应取[口二]字根序;汉字“惠”拆分不取[一虫一心]字根序,应取“[十日一丶心]字根序。 丶]字根序,应取[尸丶]字根序;汉字“曲”拆分不取[由丨]字根序,应取[日]字根序;汉字“目”拆分不取[日一]字根序,应取[口二]字根序;汉字“惠”拆分不取[一虫一心]字根序,应取“[十日一丶心]字根序。
需要注意的是,在取大优先拆分中需要兼顾直观的汉字其实是极个别的,但为了统一起见以及方便学习汉字编码,在《附表一》和《附表二》给出了字根引用字或字根的拆分方案,对其它一些常见的非字根字构件的拆分方案,请参看《附表四:常见非字根字构件拆分方案》。
(三)对单笔画汉字的拆分
为了使单笔画汉字也能够进行汉字拆分,本输入法规定每个单笔画汉字(或字根)都可拆分为两个与该汉字(或字根)基本笔形相同的字根。如汉字“一”可拆分为[一一]字根序;汉字“乙”可拆分为[]字根序。
六、音形方式单字编码模式和方法
段码输入法对中文输入编码采用了“分段编码”的方法,这使得段码输入法的音形单字、词组、全形三种编码模式可统一用下面的基本模式来表示:
字音码段+字根码段+补充码段
音形单字编码的全码码长为4码。在音形单字编码模式中,字音码段就是该汉字的字音码,它只有一个编码;字根码段是依汉字拆分字根序列的顺序排成的字根码序列;补充码段是当“字音码段+字根码段”码长不足4码(即字根码段只有2码)时为全码补足4码而设置的,它的来源是对字根序列的末字根参照汉字拆分规则拆分得到的首字根的字根码,它最多只有一个编码。因此,对汉字进行音形单字全码编码的方法是:
(一)若字根码段只有2码,须对字根序列的末字根进行拆分,将拆分后得到的首字根的字根码作为补充码,最后,以“字音码+字根码段+补充码”的编码作为汉字音形全码编码。
(二)若字根码段只有3码,舍去补充码段,以“字音码+字根码段”的编码作为汉字音形全码编码。
(三)当字根码段超出3码时,舍去补充码段,以“字音码+字根码段”的前3码和末码组成的编码作为汉字音形全码编码。
下面举例说明:
(一)对“砗chē”字进行音形单字全码编码:汉字“砗”的字音码为[u];“砗”字拆分字根序为[石车],字根码段编码为[iu];字根码段只有2码,须加一个补充码补足全码4码。对字根序 [石车]的末字根[车]进行拆分,字根序是[七十],首字根是[七],即补充码是[q]。按“字音码+字根码段+补充码”的编码,“砗”字的音形单字全码编码为[uiuq]。
(二)对“觕cū”字进行音形单字全码编码:汉字“觕”的字音码为[c];“觕”字拆分字根序为[牛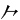 用],字根码段编码为[nby];字根码段是3码,舍去补充码段。按“字音码+字根码段”的编码,“觕”字的音形单字全码编码为[cnby]。 用],字根码段编码为[nby];字根码段是3码,舍去补充码段。按“字音码+字根码段”的编码,“觕”字的音形单字全码编码为[cnby]。
(三)对“烒shì” 字进行音形单字全码编码:汉字“烒”的字音码为[i];“烒”字拆分字根序为[火七工丶],字根码段编码为[hqgd];字根码段超出3码,舍去补充码段,以“字音码+字根码段”的前3码[ihq]和末码[d]组成的编码作为音形单字编码。故“烒”字的音形单字全码编码为[ihqd]。
七、词组编码模式和方法
前面介绍的音形编码是单字输入的音形编码,而这一节介绍的词组编码其实是单字音形编码的扩充。词组编码全码码长为词组汉字数+3,词组编码模式可简化为“词组字音码段+末汉字音形编码段”模式,其中词组字音码段是词组中各汉字的字音码的序列;由于末汉字音形编码的字音码已经加入到了词组字音码段中去了,所以末汉字音形编码段其实是词组末汉字的不带字音码的音形单字编码,或者是词组末汉字音形单字编码后3码。
下面是词组输入的举例:开辟[kpioi]、天安门[tamdiv]、神态安闲[itaxmmc]、理论与实践[llyijzgh]、阿尔卑斯山脉[aebsimyde]、春色满园关不住[usmygbvrdw]、政治局常务委员会[vvjuwwyhres]、壹贰叁肆伍陆柒捌玖[yesswlqbjwbd]。
目前版本本输入法容纳词组汉字的个数最高是9个。
由于段码输入法的词组输入简便快捷,且词组量大(现版本已有八十多万词条),简码率高,重码率低,所以更容易实现中文的高速录入。
八、全形输入方式
全形编码是单字输入的编码,全形编码模式是仅依据汉字字形条件进行编码的模式,所以汉字全形编码可以简化为下面模式表示:字根码段+补充码段。
全形编码模式全码码长为4码。字根码段是依汉字拆分字根序列的顺序排成的字根码序列;补充码段是当字根码段不足4码时为全码码长补足4码而设置的,它的来源是对字根序列的末字根参照汉字拆分规则拆分后排前的字根的字根码得到,且最多取2个字根码。当字根码段超出4码(含4码)时,舍去补充码段,以字根码段的前3码和末码组成的编码作为汉字全形全码编码。
下面举例说明:
(一)对“砗”字全形编码:“砗”字拆分字根序为[石车],字根码段为[iu];字根码段只有2码,须加2个补充码补足4码。对字根序 [石车]的末字根[车]进行拆分,字根序是[七十],取排前的2个字根[七十]的字根码[qi]作为补充码段。按“字根码段+补充码段”的编码模式,“砗”字的全形全码编码为[iuqi]。
(二)对“觕”字全形编码:“觕”字拆分字根序为[牛用],字根码段为[nby];字根码段只有3码,须加1个补充码补足4码。对字根序[牛用]的末字根[用]进行拆分,字根序是[月丨],取排前的字根[月]的字根码[y]作为补充码。按“字根码段+补充码段”的编码模式,“觕”字的全形全码编码为[nbyy]。
(三)对“烒”字全形编码:“烒”字拆分字根序为[火七工丶],字根码段编码为[hqgd];字根码段刚好4码,舍去补充码段,以字根码段的编码作为汉字全形编码。故“烒”字的全形全码编码为[hqgd]。
(四)对“鄨”字全形编码:“鄨”字拆分字根序为[丷巾八攵口巴],字根码段编码为[ejbwob];字根码段超出4码,舍去补充码段,以字根码段的前3码[ejb]和末码[b]组成的编码作为汉字全形全码编码。故“鄨”字的全形全码编码为[ejbb]。
段码输入法版权人:李梧杰
|
